
Subscribe to join thousands of other ecommerce experts
In my last post, I discussed the challenging task of automated, item-level bidding in Google Shopping, and revealed how smec’s data science team goes about designing an AI-based solution.
We start by clearly defining the problem and choosing the appropriate data, and then we engineer this data to make it as useful as possible for our machine learning models. Next, we build and train those models, and tweak them to perfection. It’s a great sneak-peek into the daily life of a data scientist in an industry setting, so if you haven’t read it yet, take a look.
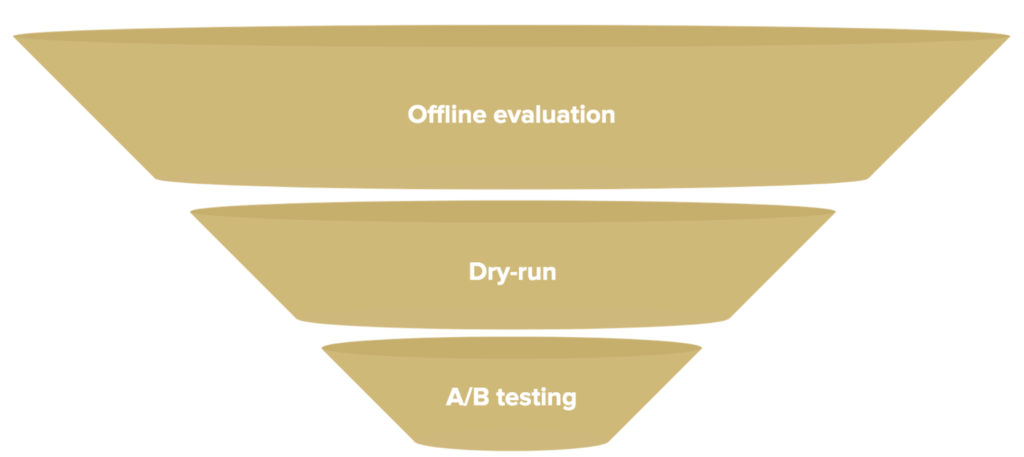
Whenever we build or improve on a machine learning model, we need to thoroughly test it to ensure it benefits all customers. We’ve developed a testing pipeline inspired by the pharmaceutical industry to do just that. Just like in a medical clinical trial, a proposed new drug must move through three stages and show real benefits at each one.
To see how our testing procedure reflects this, let’s walk through it with a hypothetical case study: introducing a new input feature to a model.
For those who need a recap from the last post, our AI solution automatically generates item-level bids for any product in a retailer’s inventory, on any browsing device, at any time. To do this, we train various machine learning algorithms to predict certain aspects of performance, which are used to calculate the best possible bid.
The training data consists of ‘features’, carefully chosen aspects of the catalog and performance data. Each time we develop a new input feature for our models, we must test its effectiveness, before we can finally deploy the change.
Table of Contents
Stage 1: Offline Evaluation
In this step, we train both the current ‘live’ model and the model with the proposed new feature on a large amount of historical catalog data and the corresponding products’ performance metrics. Then we ask both models to make performance predictions for a subsequent historical period, and verify these against the true performance results achieved in that time. Various statistical methods are used to measure accuracy and error rate of both models, so that we can be sure our new variant shows improvements.
This stage can be executed very quickly, since we already have all the required data. This makes it excellent for fine-tuning our proposed change if we feel the results could be even better. Furthermore, it’s a 100% safe way to try new approaches. Thus, we can quickly and constantly adapt to new market trends and insights, discovered through our own research or via smec’s customer-facing teams.
Stage 2: Dry-Run
If our model with the proposed new feature generates offline improvements, we can move to a dry-run. With Whoop! continuously receiving information on new products and their Google Shopping campaign performance, we train both model variants on this data and query both for their predictions.
Crucially, the predictions from the new variant are never used to generate bids, so we are still 100% safe. We again check machine learning metrics, like error rate, and now also check that the bids which would have been produced using the new model’s predictions make sense from a business perspective. For example, if the model has discovered certain products have untapped revenue potential, then we might expect the bids to be higher, but not astronomically so.
Stage 3: A/B Testing
Arriving at stage three means we are confident we’re working with something great, having seen improvements to machine learning metrics and a reasonable effect on business indicators via the proposed bids. Now, it’s time to carefully go live.
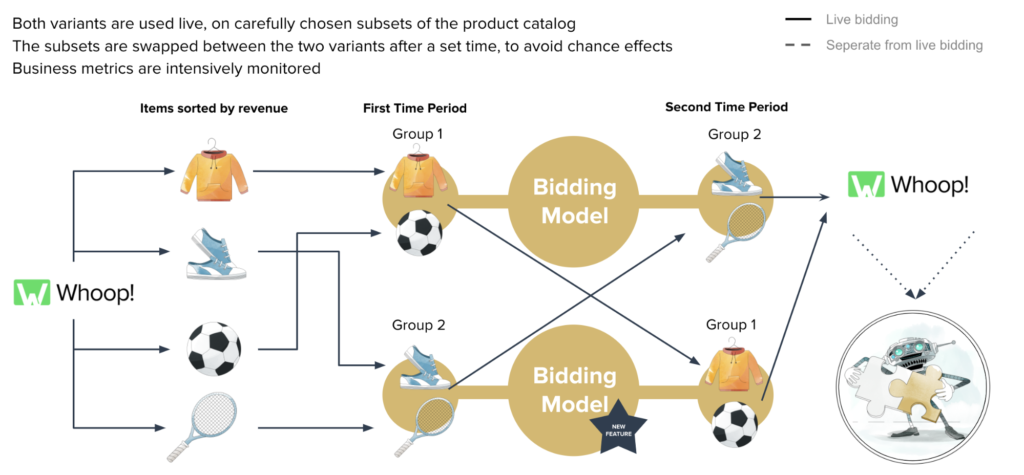
Both variants of the model receive a subset of the product catalog, and are trained on live data and used to generate real predictions and bids. Just as patients are carefully chosen in a clinical trial, so too are the catalog subsets, as we randomly spit them in a way that nevertheless ensures the expected performance is balanced across the sets. After a predefined period we swap the subsets, so that both models have the chance to work on each.
In stage three, we can observe machine learning measures such as accuracy, business indicators such as average CPC, and – finally – the true effect on business metrics such as turnover and ROAS. If the new model variant continues to outperform the other (which, having gotten this far, it generally does!), we can safely roll out the change for the entire catalog.
Going live doesn’t mean ‘Set and forget’
In the data science team, we are driven by a desire to constantly innovate and improve. Our custom-built dashboards give continuous insight into how the models are doing, and our alerting system lets us react immediately to any significant changes caused by unexpected events.
Sometimes this reveals new areas for improvement, and our close relationship with smec’s customer-facing teams means client feedback can always be used to derive new ideas. Furthermore, given our team’s diverse academic backgrounds and engagement with the latest research, we are constantly discovering new ways to potentially improve our bidding models.
This is particularly important in dynamic markets, where changing competitors, sales events, trends and so on make fast adjustments essential.

Whenever an improvement is proposed, we start with targeted research in the applicable domain, and use descriptive statistics to better understand our data from this new perspective. Next, we create quick prototypes, a.k.a. ‘model sandboxing’, to see whether the idea has promise. And if it does, the entire testing pipeline begins again.
source on Google →

